



第三章 二维基本图形光栅化与裁剪
3.1 光栅化问题概述
在光栅显示器设备上,所有图形的显示对应显示器上的光栅像素点亮。复杂的图形看作是由一些基本图形元素(图元)构成,基本二维图元包括点、直线、圆弧、多边形、字体符号和位图等。三维图形的显示最终也是通过投影转化成二维图形的显示。
接下来我们要学习的内容就是如何把图元所对应的像素点亮,同时要求我们的性能开销比较小。这个过程就称为光栅化。
3.2 直线段光栅化
直线的定义:起点(x_0,y_0),终点(x_1,y_1)。我们要寻找的东西就是我们要点亮的像素点集合。其中这些像素间不能够出现间隙,还有比较合适的粗细。
下面我们由浅入深的讨论几种算法:
直接法
通过直线的两个端点,我们能构造直线的定义式:
y=kx+b
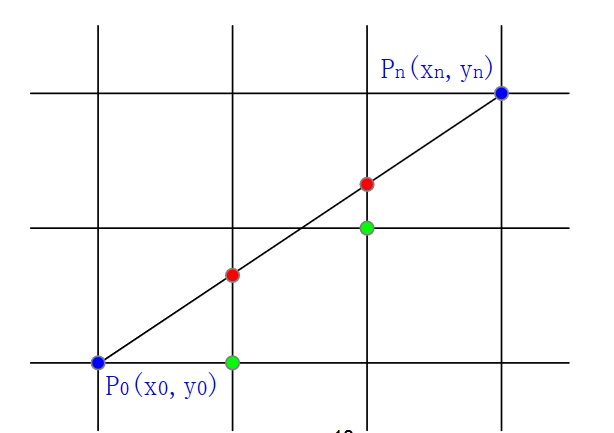
其中k=\frac{y_n-y_0}{x_n-x_0},b=y_0-kx_0。将x的步长设为1进行遍历,得到不同x情况下y的取值,由于我们的像素点坐标值为整数,需要将算出的y值进行四舍五入,这样我们就画出了一条直线。程序的伪代码如下:
LineSimple(int x0, int y0, int xn, int yn)
{
k = (xn-x0)/(yn-y0);
b = y0-k*x0;
y = y0;
for(x = x0;x <= xn;x++)
{
Pixel(x,(int)(y+0.5));
y = k*x+b;
}
}
在以上的这个程序中,我们发现在循环体中需要多次计算乘法,即k*x对于计算机来说,计算乘法远比计算加法困难得多,于是我们就可以对这个地方进行改进。
数值微分法 DDA
在上面的方法中,在循环体里需要不停求解的是y的值,很容易观察到y有这样一个递推式:
y_k=y_{k-1}+k
于是我们就能再一次优化我们的直线光栅化代码:
LineDDA(int x0, int y0, int xn, int yn)
{
k = (xn-x0)/(yn-y0);
b = y0-k*x0;
y = y0;
for(x = x0;x <= xn;x++)
{
Pixel(x,(int)(y+0.5));
y += k;
}
}
以上这种方法称为数值微分法(DDA)。
以上的讨论建立于0<k\le 1的情况下,下面我们讨论其他中情况:
对于斜率更大的情况,应该将y以步长为1进行循环求解计算。通过直线的方程,在y每进1步时,x的增量计算如下:
x_{k+1}=x_k+\frac 1k
至此,我们只是解决了第一象限的直线绘制方式,DDA绘制直线时总共有8种情况:
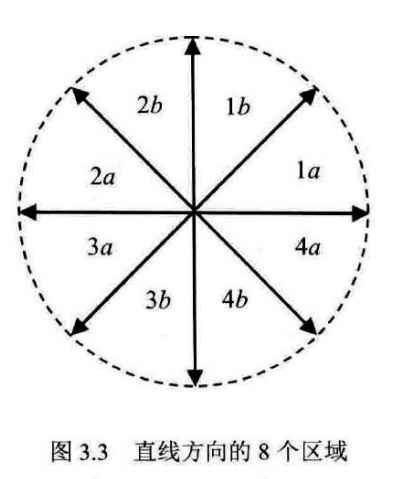
这八种情况对应的步长和增量如下表:
| 区域 | \mathrm dx | \mathrm dy |
|---|---|---|
| la | 1 | k |
| 1b | 1/k | 1 |
| 2a | -1 | k |
| 2b | -1/k | 1 |
| 3a | -1 | -k |
| 3b | -1/k | -1 |
| 4a | 1 | -k |
| 4b | 1/k | -1 |
Bresenham 画线法
如果你足够细心,就很容易发现在讨论0<k\le1情况下时,当前点对应的下一个点只有两种情况:它的正右方或者是它的右上方。那我们转换一种思路,我们在每次循环计算的时候,只判断一下哪个点应该被涂色,然后将这个点作为当前点再次递归。
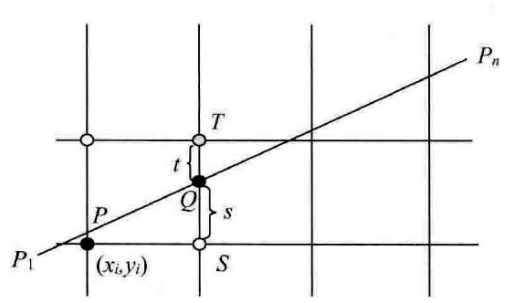
由图易知:S的坐标是(x_i+1,y_i),T的坐标是(x_i+1,y_y+1)。
因此:
\begin{cases} s=y-y_i=k(x_i+1)+b-y_i\\ t=y_i+1-y=y_i+1-k(x_i+1)-b \end{cases}
得到:
s-t=2k(x_i+1)+2b-2y_i-1
我们将k=\frac{\mathrm dy}{\mathrm dx},并设d_i=\mathrm dx(x-t),综合可得到递推式:
d_{i+1}=d_i+2\mathrm dy(x_{i+1}-x_i)-2\mathrm dx(y_{i+1}-y_i)
我们假设x的步长为1,可以得到:
d_{i+1}=d_i+2\mathrm dy-2\mathrm dx(y_{i+1}-y_i)
由于该式只包含了加减法和左移(乘2)的运算,所以效率也很高。
对于一般情况,也就是k不限的情况,我们还和之前的做法一样,当|k|>1时,将y作为步长来递增,通过\mathrm dx或者\mathrm dy的符号来判断步长是+1还是-1。
上述方法被称为Bresenham画线法。
中点画线算法
下面给出一种与Bresenham方法效率相同的方法,我们还是假设0<k\le 1:
与Bresenham算法类似,我们还是要寻找两个点中最合适的那个填充点。不过我们的判别方法有所改变:
还记得我们的直线斜率式吗,现在我们把它改为一般式:
F(x,y)=y-kx-b=0
根据高数的知识我们可以知道,欲判断一点在直线的上方还是下方,只需将该点带入直线的一般式,通过正负进行判断。将待判断的两点的中点带入直线一般式:
d_i=F(x_i+1,y_i+0.5)=y_i+0.5-k(x_i+1)-b
当d_i>0,应取右方的点,当d_i<0,应取右上方的点,当d_i=0,这里约定取右方的点。这样我们也能求出递归式:
\begin{cases} d_{i+1}=d_i+1-k,\quad&d_i<0\\ d_{i+1}=d_i-k,&di\ge0 \end{cases}
在循环体中仅计算了整数,效率也很高。这种方法称为中点画线算法。
3.3 圆弧光栅化
如果我们要绘制整个圆,那么我们可以仅仅绘制其中的一小部分,然后根据对称性来补齐其余的部分。在计算机中常用的是八分画圆法,我们仅需计算圆的八分之一的像素,其余通过对称补齐即可:
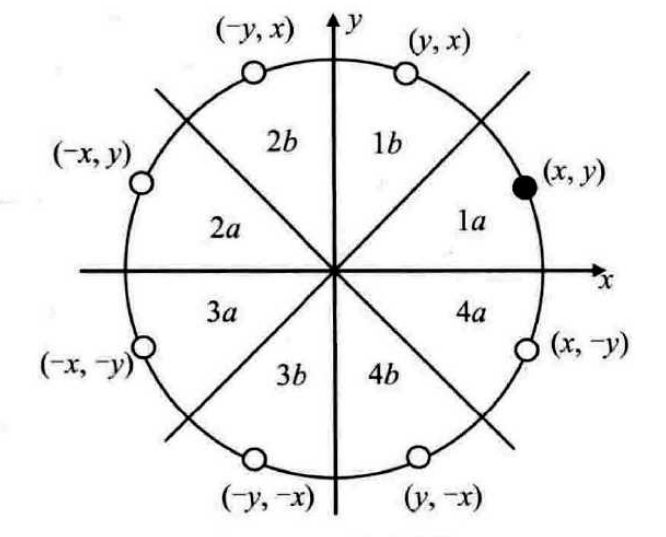
Bresenham画圆算法
在此部分仅对1b部分进行讨论。
如何确定一个圆,通过数学可以知道当确定圆心的坐标和半径就能够确定一个圆的实际形状。在这里将圆心坐标记作:(x_0,y_0),半径记作r。因此需要点亮的第一个像素就是(x_0,y_0+r),利用四舍五入将每个坐标值都化作整数。我们将已知点记作P,有以下两个点T,S需要我们进行判断:
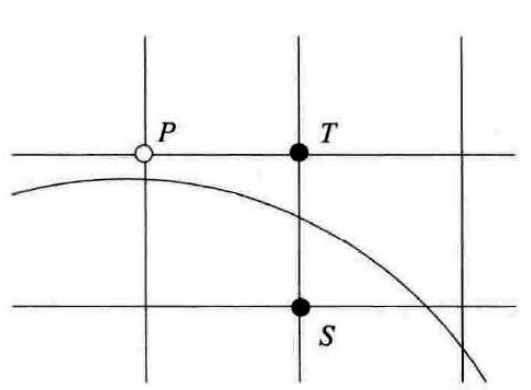
令D(T)为T点到原点距离的平方与半径的平方之差,D(S)同理。
D(T)=(x_i+1)^2+y_i^2-r^2\\ D(S)=(x_i+1)^2+(y_i-1)^2-r^2
设d_i=D(T)+D(S),当d_i<0时,选择像素T,当d_i\ge0时,选择像素S。
同时我们也能得到递归式:
\begin{cases} d_{i+1}=d_i+4x_i+6\quad&d_i<0\\ d_{i+1}=d_i+4(x_i-y_i)+10&d_i\ge0 \end{cases}
以上称为Breseham画圆法。
中点画圆算法
与中点画线算法类似,我们将ST的中点带入到圆的解析式中,如果解析式大于0,则中点在圆外,取T点;如果解析式小于0,则中点在圆内,取S点。
d_i=F(M)=(x_p+1)^2+(y_p-0.5)^2-r^2
由上式我们也能推出递推式:
\begin{cases} d_{i+1}=d_i+2x_p+3\quad&d_i<0\\ d_{i+1}=d_i+(2x_p+3)+(-2y_p+2)&d_i\ge0 \end{cases}
3.4 区域填充
多边形填充算法
下面请思考一个问题:如何确定一个点是否被多边形所包围呢?
下面给出两种算法:
-
射线法
将该点以随意一个方向(比如说水平向右)发射,计算射线穿过多边形的边一共几次。若是奇数次则判断该点在多边形内,若是偶数次则判定该点在多边形外。
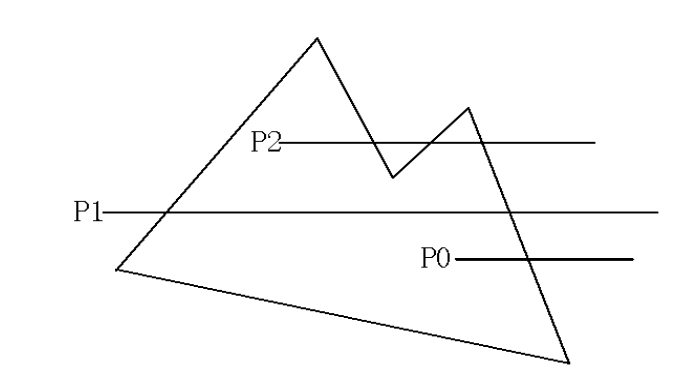
示例图
例如P_2穿过了3次,则该图形在多边形内。P_1穿过了2次,该图形在多边形外。
特判情况:如果射线经过了多边形的端点,那么穿过数需要特判。端点两端线段在射线两侧则加1,否则不加。
-
累计角度法
以预判点v和多边形P上某一点连成线段,将多边形上的点沿多边形移动一周,累加其角度。
\sum\limits^n_{i=0}\theta_i= \begin{cases} 0,&v位于P之外\\ \pm2\pi,&v位于P之内 \end{cases}
在学会了如何判断点在多边形内后,下面这个多边形填充算法将会用到:
-
逐点填充法
选定一个矩形区域,矩形区域内包含了多边形的所有边。将这个矩形区域从(0,0)点开始逐个判断点是否在多边形区域内。若在多边形内则涂色。依照这种方法将矩形区域内所有的点都进行一次特判。
这种方法在实际中并不可取,因为算法割断了像素之间的联系,大量像素需要一一判别,费时又费力。
下面提出一个改进算法:
-
扫描线填充法:
还是用矩形区域围住多边形,从y=0作为扫描线依次向上递增。判断每条扫描线和多边形的交点,将交点进行配对(比如说1、2号配对),将配对的区间范围像素全部涂色。
这种情况也需要特判,和之前讲到的射线法特判一样。如果扫描线碰到了交点,需要判断交点两端的线段在扫描线的一侧或是两侧。在一侧按两个交点记,在两侧按一个交点记。
以上算法最麻烦的地方在于求交,那么我们能不能再对扫描线填充法进行升级,简化求交的步骤呢?下面介绍终极方法:
-
活动边表填充法
-
首先我们需要建立一个边表,储存每条边的信息。多边形由几条边就存储几条边的信息,每条边的信息存储在其y值对应的交点。例如:
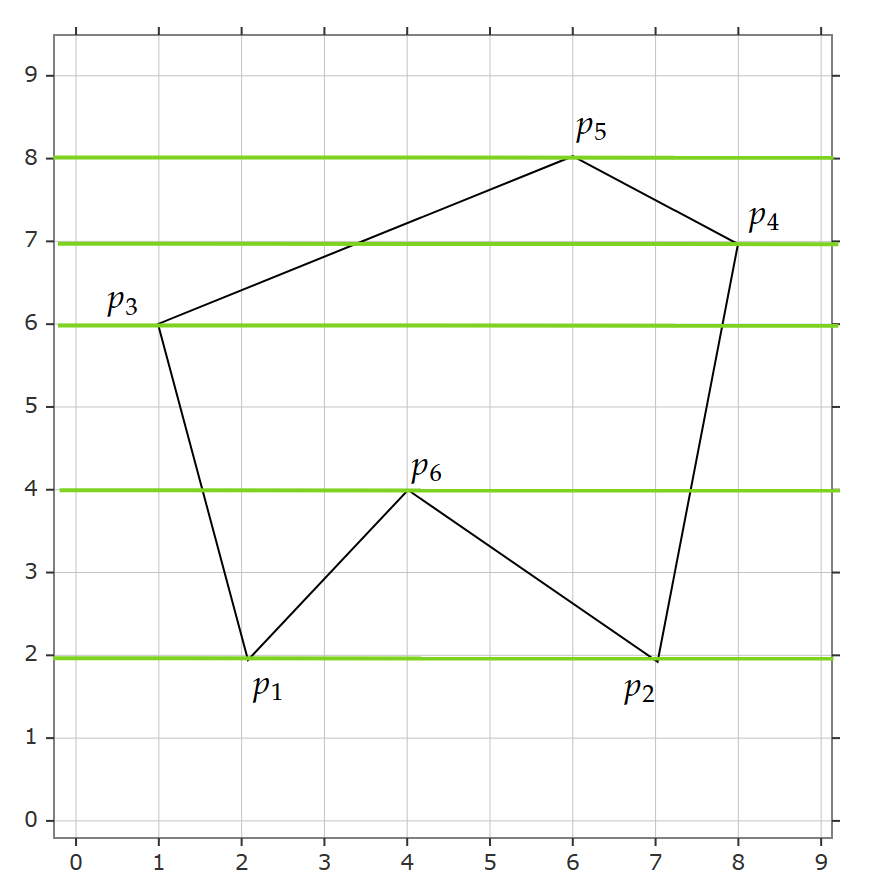
其对应的活动边表为:
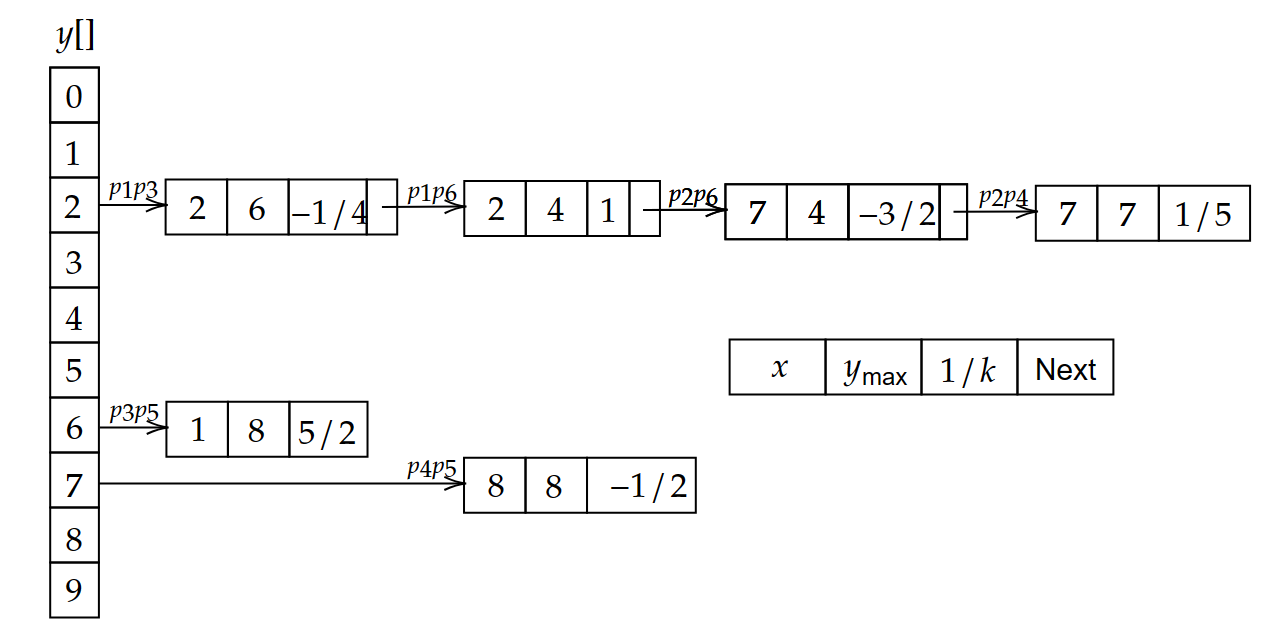
- 从0开始依次向上递增,若检测到边表的存在,则两两配对,将x坐标符合区间内的点涂色。
- 更新新的表,删除旧的表。新的表中x值对应前一个表的x+1/k。若y大于等于y_\text{max},则删除该表。
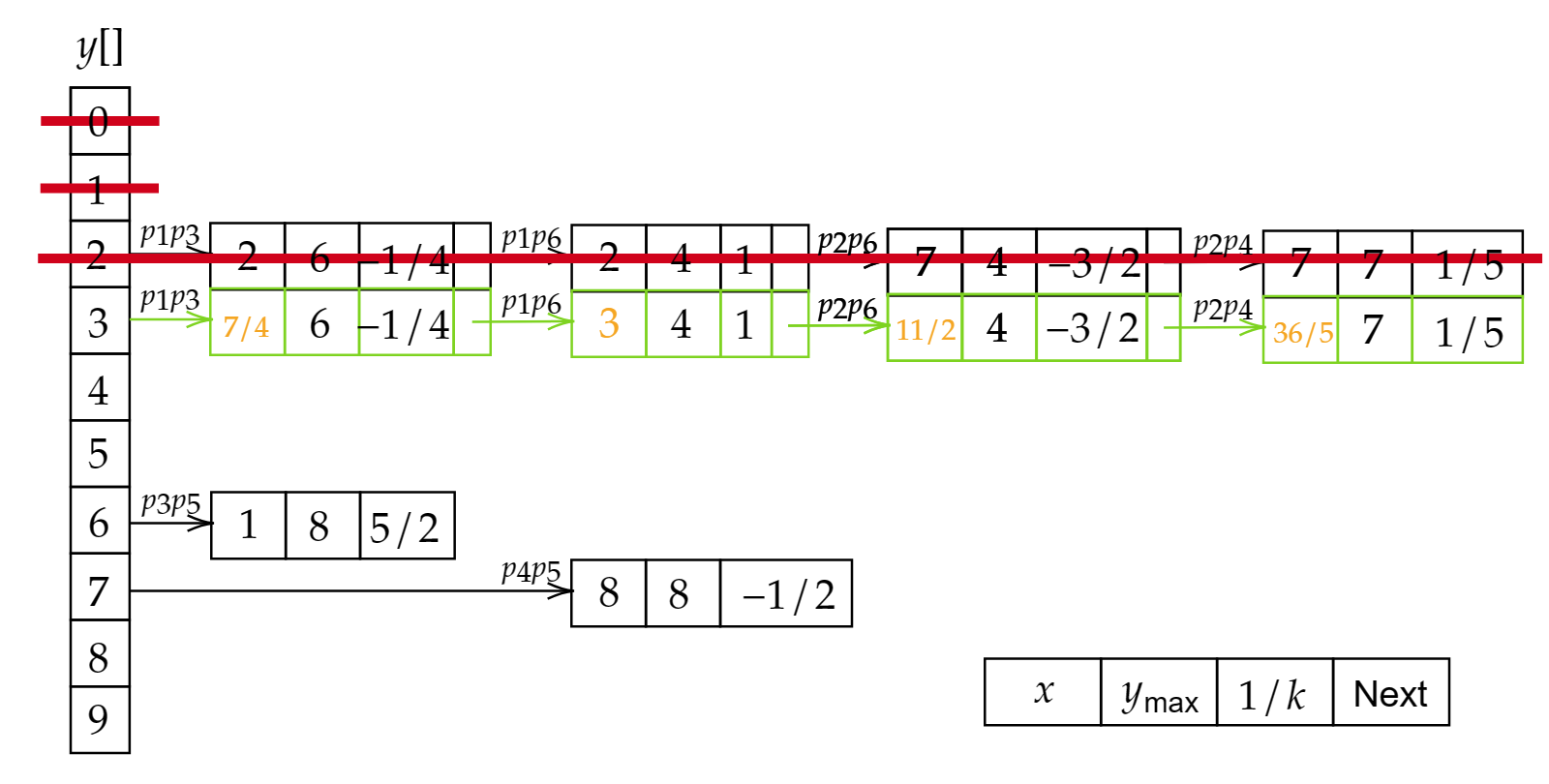
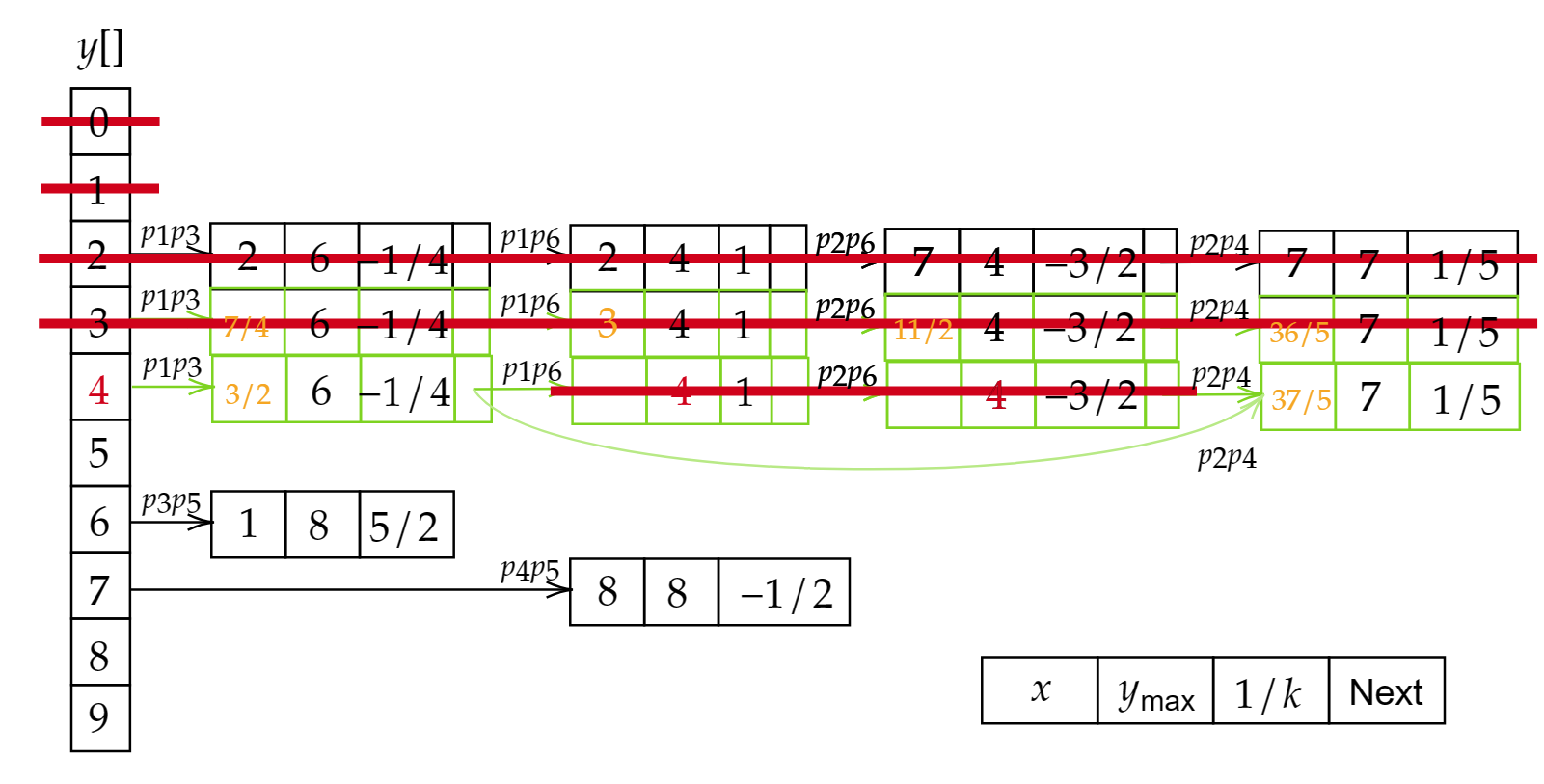
- 重复2、3,直到y遍历结束。
由于边表在不断的更新,所以称这种方法为活动边表法。
活动边表法适合软件实现,适合硬件的算法有边填充算法,这里不再赘述。
-
区域填充
若欲实现区域填充,则必须确保区域具有连通性。连通性分为四连通和八连通。四联通只包含上下左右四个像素,八连通则是像素周围的8个像素。
最简单也是最容易想到的算法是简单种子填充算法。
-
简单种子填充算法
首先将种子像素进行入栈,当栈非空时,重复执行下述三步:
- 将栈顶元素出栈;
- 将出栈像素置成多边形色;
- 按四向或八向检查相邻像素,若某个像素不在边界且未置颜色,把该像素入栈。
该算法有以下的缺点:每一个像素都会进/出栈依次,费时费内存;有些像素会入栈多次,降低效率;栈结构占空间。
-
扫描线种子填充算法
在任意不间断区间中只去一个种子像素,填充当前扫描线上的该段区间;确定与这区间相邻的上下两条扫描线上位于区域内的区段,产生种子像素。步骤如下:
- 种子像素入栈
- 当栈非空时,重复执行下述三步:
- 栈顶像素出栈;
- 填充像素所在扫描线区间段;
- 在区间中检查与当前扫描线响铃的上下两条扫描线的有关像素是否全为边界或已填充的像素,若存在非边界、未填充边界的像素,则把每一区间最右像素作为种子像素入栈。
3.5 字符
如果想要显示字符,系统中必须要有字库,用于存储每个字符的形状信息。字库分为矢量字库和点阵字库。现在的操作系统中使用的都是矢量字库。
点阵字符
将每个字符都按照一个点阵位图来表示。这对于英文字母来说可能不算什么,但对于汉字就十分致命了。如果使用72*72点阵计算10个不同字体和十个不同字号,6763个汉字需要有418MB的存储空间。
矢量字符
将字符表达为一个点坐标的序列,相邻两点表示一条矢量,字符的形状由矢量序列刻画。字符的轮廓线可以用直线、Bezier曲线来描述字符。在Windows中,使用的时TrueType字型技术。保存好所需要的字符轮廓信息后,使用多边形填充的方法将字符的颜色进行填充。
3.6 反走样技术
用离散量表示连续量必然会导致失真,在图形中称为走样。走样的现象表现为下述几种情况:
- 阶梯状边界,也就是我们说的锯齿;
- 图形细节失真;
- 狭小图形遗失。
而用于减少或消除走样现象的技术称为反走样。反走样的简单方法如下:
提高分辨率
将显示器的分辨率提高一倍,输出的图形会更细腻,锯齿感会减少,图形显示更加细腻。
这种方法虽然简单,但代价非常大,不仅我们的显示器需要支持高分辨率,我们的处理设备也要处理计算更多。
软件方法可以先使用高分辨率先显示图形,再用较低的分辨率下显示。例如将单个像素分为四个子像素,求得各子像素的灰度值,然后对四个像素进行简单的加权平均,得到该像素的灰度值。
简单区域取样
将直线看作具有一定宽度的狭长矩形,当直线段与某像素有交时,求出两者相交区域的面积。然后用面积与总面积的比值来确定灰度值的大小。
加权区域取样
确定灰度值大小时,使用不同的滤波器给其灰度值加权,使其看起来更加理想。常用的过滤函数有立方体滤波、圆锥滤波和高斯滤波。
3.7 裁剪
裁剪是计算机图形学许多重要问题的基础,裁剪典型应用就是从一个大的场景中提取所需要的信息。被裁减的对象可以是点、线段、圆弧段、多边形、字符以及由它们构成的各种图形。二维的裁剪窗口通常为一个矩形范围,而三维空间的裁剪窗口通常被称为裁剪空间。
点的裁剪
点的矩形裁剪相对简单,当点(x,y)在矩形区域内,则保留,否则则移除。
设矩形窗口的左下角点为(x_L,y_B),右上角点为(x_R,y_T),只需要判断下面的两个不等式即可:
\begin{cases}
x_L\le x\le x_B\\
y_B\le y\le y_T
\end{cases}
如果两个不等式都成立,则点在矩形窗口内,否则点在矩形窗口外。
判断点是否在多边形内,在之前的多边形填充算法中有所介绍。
直线裁剪
下面的裁剪都是矩形裁剪。
1. Cohen-Sutherland 裁剪法
Cohen-Sutherland 算法是一个经典的编码算法,该算法的主要思想是:对于每条线段,分为三种情况处理:
- 若线段完全在窗口之内,则显示该线段;
- 若线段完全在窗口之外,则丢弃该线段;
- 若线段部分在窗口之内,则将线段分割成两段,只保留线段在窗口之内的部分。
为了快速判断一条直线段与矩形窗口的位置关系,采用了如图所示的编码方案。把图形区域分为9个区,每个区都有一个4位的二进制编码。从左到右依次为上、下、右、左。例如左下方的区域编号为0101,中间区域的编号为0000。

欲判断线段的位置,我们只需要判断该线段的顶点在9个区的位置即可。例如恒在中心区的端点(code1 == 0 && code2 == 0),我们可以全部保留;对于两个端点都在一侧(code1 & code2 != 0),即编号的某位均为1时,则全部丢弃。其余情况则需要具体判断。
第三种情况,需要求出线段与窗口某边的交点,在在焦点处把线段一分为二,其中在窗口之外的线段部分直接丢弃。对其与保留的线段继续进行处理。这种算法在寻找线框与线段的交点时性能开销较大。
2. Liang-Barsky 参数化裁剪法
Liang-Barsky 算法是一种更好更快的算法,设要裁剪的线段时P_1P_2,P_1的坐标为(x_1,y_1),P_2的坐标为(x_2,y_2),p_1p_2与窗口的边界交于A、B、C、D四点,算法的基本思想是,从A、B和P_1中找出靠近P_2的点,图中找出的点是P_1,从C、D和P_2中找出最靠近P_1的点,找出的点是C,那么P_1C就是P_1P_2线段上的可见部分。

具体算法如下:
-
确定参数
设\Delta x=x_1-x_0,\Delta y=y_1 - y_0。 -
根据\Delta x和\Delta y来确定始边和终边:
- 若\Delta x\ge0,则x=x_L为始边,x=x_R为终边。若\Delta x<0,则x=x_R为始边,x=x_L为终边。
- 若\Delta y\ge0,则y=y_B为始边,y=y_T为终边。若\Delta y<0,则y=y_T为始边,y=y_B为终边。
-
计算u_L,u_R,u_B,u_T:
\begin{cases} u_L=(x_L-x_0)/\Delta x\\ u_R=(x_R-x_0)/\Delta x\\ u_B=(y_B-y_0)/\Delta y\\ u_T=(y_T-y_0)/\Delta y \end{cases} -
确定始参u_s和终参u_e:
\begin{cases} u_{sx} = u_L,u_{ex} = u_R,\Delta x>0 \\ u_{sx} = u_R,u_{ex} = u_L,\Delta x<0 \\ u_{sy} = u_B,u_{ey} = u_T,\Delta y>0 \\ u_{sy} = u_T,u_{ey} = u_B,\Delta y>0 \\ \end{cases}
u_s = \max{(u_{sx},u_{sy},0)}\\ u_e = \max{(u_{ex},u_{ey},1)} -
确定区间
若u_s\le u_e则裁剪结果为区间[u_s,u_e],否则丢弃。
多边形裁剪
Sutherland-Hodgeman 算法
Sutherland-Hodgeman的处理策略分割处理策略,即将多边形关于矩形窗口的裁剪分成窗口的四条边钓鱼所在直线的裁剪,其裁剪的过程为左上右下。
设多边形各条边的两端点为S、P。它们与裁剪线的位置关系只有四种。

- 对于情况(1),输出点P;
- 对于情况(2),无输出;
- 对于情况(3),输出交点I;
- 对于情况(4),输出交点I和点P。
对于凸多边形本算法能够得到正确的结果,但是对于凹多边形的裁剪将会显示出一条多余的直线。
下面介绍一种不会出现多余直线的算法:Weiler-Atherton算法。
Weiler-Atherton 算法
假定按顺时针方向处理顶点,将用户多边形定义为P_s,将窗口矩形定义为P_w。算法从P_s的任意一个点出发,跟踪P_s的每一条边。当P_s和P_w相交的时候,称该焦点为实交点。实交点按以下规则处理。
- 若是由不可见一侧进入可见一侧,则输出可见直线段,转3。
- 若是由可见侧进入不可见侧,则从当前交点开始。沿窗口边界顺时针前进,找到P_s与P_w最靠近当前交点的另一交点,输出可见线段和两交点之间的线段,然后返回当前交点,转3。
- 沿着P_s处理各条边,直到返回起点为止。
该算法既利用了多边形的各条边来处理顶点,又运用了窗口边界来处理顶点。
文字裁剪
文字裁剪有三种情况:串精度裁剪、字符精度裁剪和笔划、像素精度裁剪。
评论区